
The problem
Most small companies have the same setup: knowledge sprawled across Wiki, Google Docs, and Notion. Three places, three search bars, three permission systems. New hires bounce between systems to find a simple SOP. Senior employees get tapped daily for things already documented somewhere they can’t find. The KM becomes write-only.
I had been watching this play out at the company I work at — a 30-person e-commerce business with policies in HR Word docs, SOPs in Wiki.js, product specs in Notion. Then a colleague asked me, “Where’s the customer escalation flowchart again?” for the third time in a month, and I decided to actually do something about it.

The idea
Put one conversational interface in the place people already are — Microsoft Teams — and have it search everywhere at once.
The bot would:
- Sync from Wiki.js, Google Docs, and Notion on a schedule
- Answer questions using RAG (retrieval-augmented generation), citing the source document
- Let people contribute new knowledge as easily as messaging — quick notes that turn into published KB pages with one command
The bar I set: it had to be better than asking a senior coworker, not just barely useful.
What I built
Multi-source RAG with query rewriting
The naive RAG pipeline (embed user question → cosine search → generate answer) works fine on prepared demos but fails the moment a user types something vague. Real users type things like “where do I configure LINE push?” — and the closest doc, “LINE 推播設定”, scores below noise because of the word “configure” pulling toward UI/config docs.
The fix: before searching, expand the question into 2-3 semantic variants with GPT. Search each variant, then merge by max score per chunk. Recall improved dramatically on the kinds of bare-noun questions people actually ask.
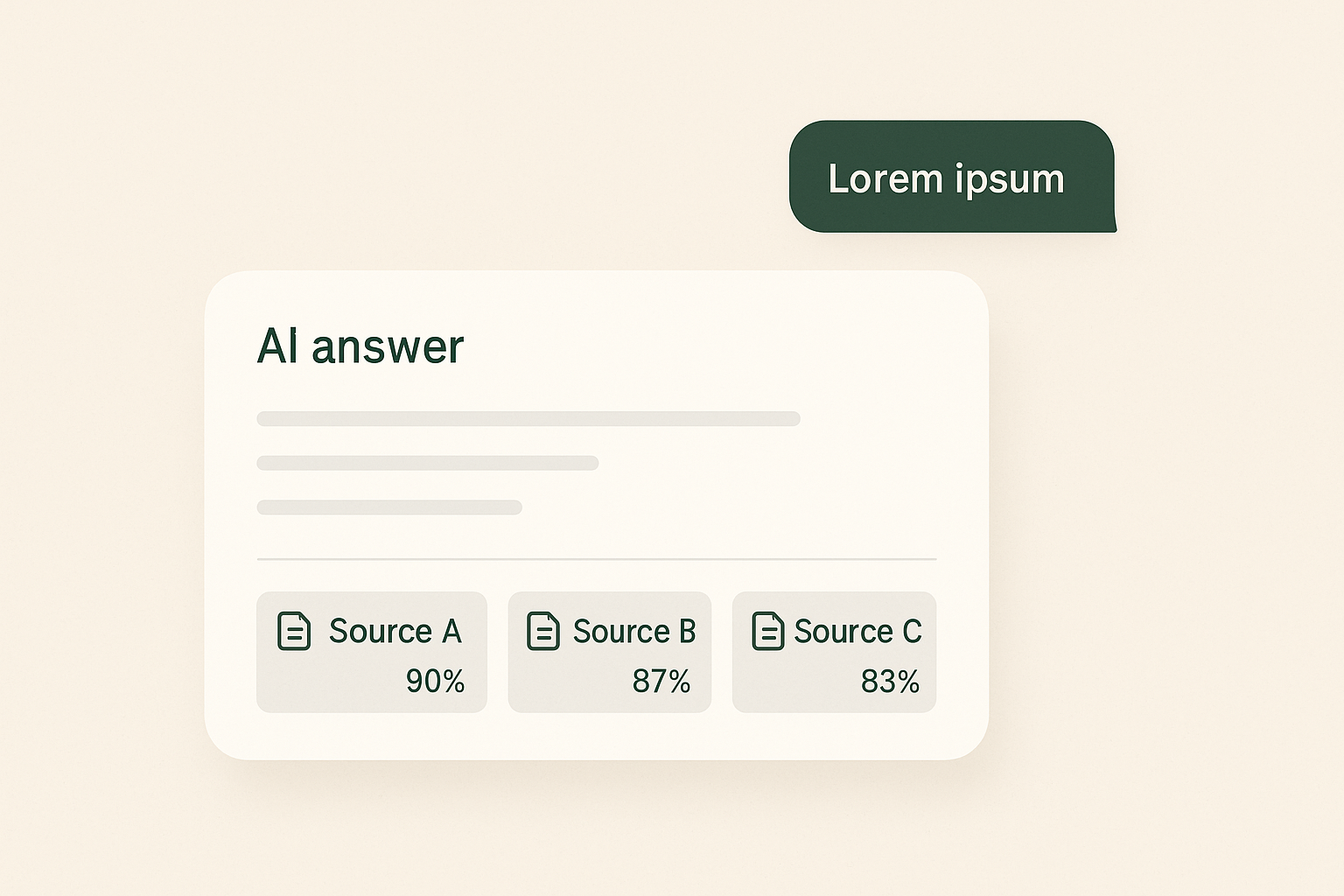
Write-back to the knowledge base
The killer feature isn’t the search — it’s that the bot can also edit, append, and publish back to all three sources.
#edit lets anyone fix a typo in Wiki.js without learning the CMS. #append lets them add a missing step to a SOP. #publish turns a Slack-style note into a polished KM page (AI fills in title and structure). Each Notion edit even adds an audit trail since Notion has no per-block edit history.
The result: the knowledge base gets continuously corrected by the people who notice issues, not by an editor who has to be flagged. Knowledge contribution stops being a meeting-scheduled task and becomes a habit.
Personal assistant features
I added notes and reminders on top, because the same UI was already there. Now the bot also serves as a per-user notepad. The daily 9/14/17 reminder push has its own little engineering story (see “Lessons” below) — it shouldn’t have been hard, and yet.
Image support throughout
Users can attach images to notes and reminders. Images are stored in private Azure Blob with per-render SAS tokens, never public URLs. When a note publishes, images get embedded in KM (as base64) or inserted into Google Docs (via Drive), and the original blob is deleted. The original storage is intentionally short-lived.
How it’s holding up
Live in production for a few months now. Steady ~5,000 indexed chunks across three sources. Hourly sync, sub-3-second response times, ~NT$2,500/month total Azure cost.
The actual usage I find most interesting:
- Customer service uses it to look up policy thresholds while on the phone
- New hires use it as a self-service onboarding tool — HR has fewer “where’s the form?” interruptions
- A subset of power users has internalized
#publishand now uses the bot as their main publishing flow into the KB
The KB itself has grown faster than before. Not because anyone is asked to contribute — because the friction is low enough that contributing is now a side effect of using the tool.
What I learned (the interesting bugs)
A few things that took real production usage to surface:
node-cronsilently fails on long-running processes for hour-level schedules. Short schedules (*/5) stay alive. I shipped a fix that “should” work, but the fix only ran on restart — and the bot hadn’t restarted. Real fix: a 10-minute polling safety net that doesn’t depend on cron at all.- Azure App Service defaults to 32-bit workers, capping Node heap to ~90MB regardless of
--max-old-space-size. With a 6000-chunk vector store I OOM’d within the hour. One CLI flag away from working. wwwrootgets wiped on every zip-deploy, includingdata/if you store the vector store there. Lost a knowledge base this way before I learned. The fix: env-driven paths pointing to persistent storage.- Teams sends
image/*as content-type (a wildcard, not the actual mime), and thecontentUrlrequires Bearer auth. Multiple wrong assumptions to unlearn.
I wrote a longer postmortem in the repo, including the architecture choices and the parts I’d build differently.
What I’d build next
- Image OCR during ingestion — many SOPs have key info in screenshots that pure text RAG can’t see
- Hybrid search (BM25 + dense) — better for proper nouns and IDs, which dense retrieval is genuinely weak at
- Configurable LLM provider — currently locked to Azure OpenAI for one practical reason (geo restriction on direct APIs from APAC); the right abstraction would let companies swap to OpenAI, Anthropic, or Bedrock
Tech stack
TypeScript, Node.js, Azure OpenAI (gpt-4.1 + text-embedding-3-small), Microsoft Bot Framework, Wiki.js GraphQL, Google Drive API + Docs API, Notion API, Azure Blob Storage, Azure SQL, Application Insights. Hosted on Azure App Service.
Source code is on GitHub — the README has the full architecture writeup if you want the technical version.