
問題
大部分小公司都長得差不多:知識散落在 Wiki、Google Docs、Notion 三個地方,三個搜尋框、三套權限。新人在系統間切換找一份 SOP;資深同事每天被打斷回答早就寫過的問題;KM 變成「只寫不查」的系統。
我所在的電商公司就是這樣 —— 30 個人,HR 政策放在 Word 檔、SOP 在 Wiki.js、產品規格在 Notion。直到有同事一個月內第三次來問我「客訴升級的流程圖在哪?」,我決定動手做點什麼。

構想
把一個對話介面放進大家本來就會用的工具 —— Microsoft Teams —— 然後讓它一次搜遍所有來源。
這個 Bot 要做的是:
- 定時從 Wiki.js、Google Docs、Notion 同步內容
- 用 RAG(檢索增強生成)回答問題,並引用原文出處
- 讓貢獻新知識像傳訊息一樣簡單 —— 隨手記一段 → 一個指令發布成 KM 頁面
我設的標準:要做到比直接問資深同事還好用,不能只是「勉強堪用」。
做了什麼
帶查詢改寫的多來源 RAG
天真的 RAG 流程(把問題 embed → cosine 搜尋 → 生成答案)在簡報 demo 看起來很好,但碰到真實使用者就破功。真實使用者打的是「Line 推播設定位置?」這種模糊問句 —— 正確文件「Line 推播設定」被「位置」這個詞拉去 UI 設定類文件,分數連前五都進不了。
解法:搜尋前先用 GPT 把問題展開成 2–3 個語意變體,每個變體都搜,然後依每段內容的最高分合併排序。對使用者實際會打的那種短句問題,召回率有顯著提升。
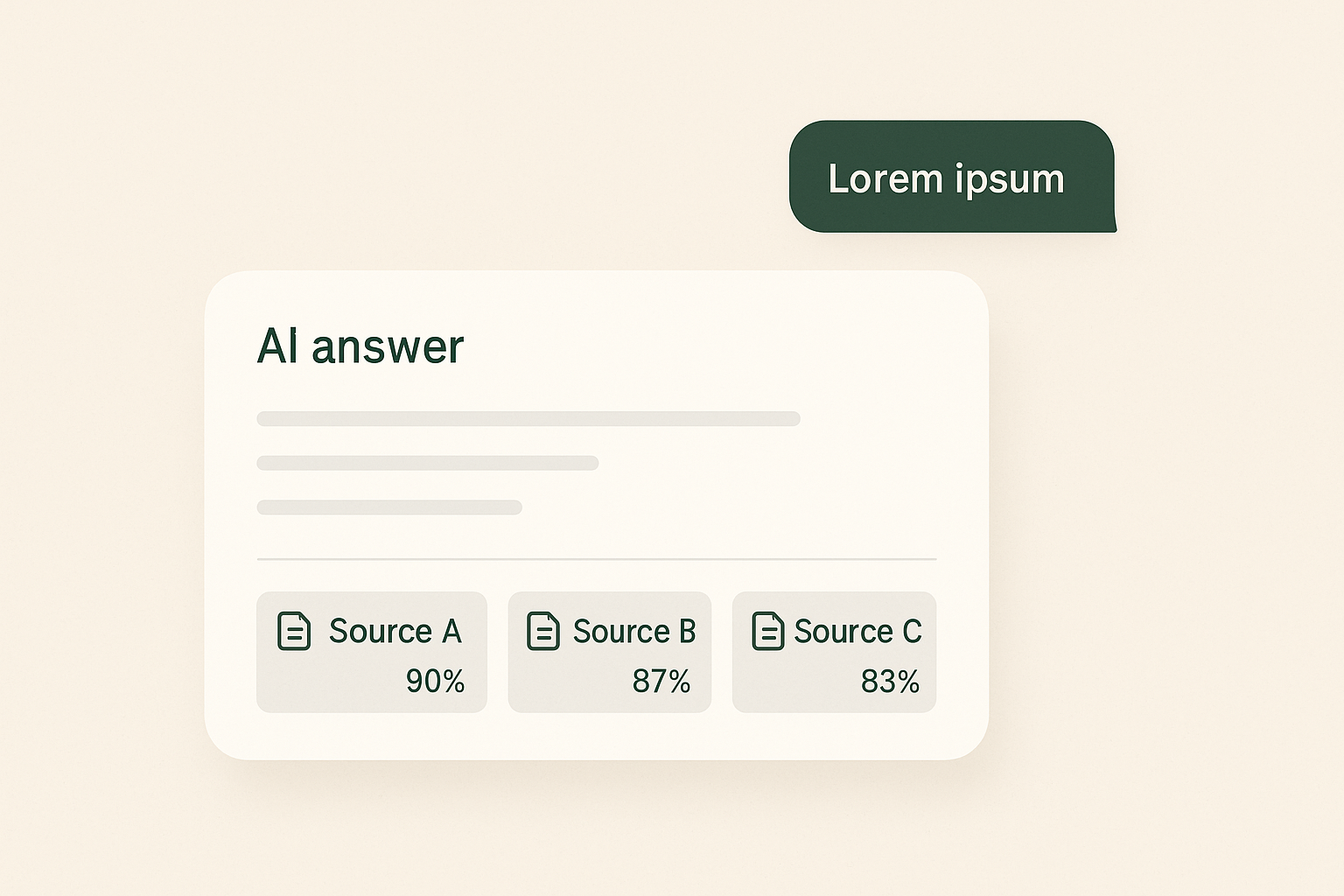
把知識「寫回」知識庫
真正的關鍵功能不在搜尋 —— 而是 Bot 還能修改、附加、發布內容回到三個來源。
#修改 讓任何人不用學 Wiki.js 後台就能修一個錯字。#追加 讓他補一個 SOP 漏掉的步驟。#發布 把一段隨手記轉成排版整齊的 KM 頁面(AI 幫你補標題和結構)。每一次 Notion 修改還會自動加上一筆稽核註記 —— 因為 Notion 沒有 per-block 編輯歷史。
效果:知識庫被「真正注意到問題的人」持續修正,而不是等某個編輯被通知再去改。貢獻知識從「要排時間做的事」變成「順手就做」。
個人助理功能
我順手在上面加了筆記和提醒功能 —— 反正 UI 都在了。Bot 同時也是個人的便利貼。每天 9/14/17 點的提醒推送背後有個小工程故事(見下面「踩過的坑」)—— 本來應該很簡單,結果並不。
全流程的圖片支援
使用者可以在筆記和提醒裡附圖。圖片存在私有 Azure Blob,每次顯示產生短期 SAS token,沒有任何公開 URL。筆記發布時,圖片會嵌入 KM(base64)或上傳到 Google Docs(透過 Drive),原始 blob 隨即刪除 —— 暫存生命週期刻意做短。
實際運作狀況
正式上線運作幾個月了。穩定維持 ~5,000 個索引切片、三個來源、每小時同步、回答時間 < 3 秒、每月 Azure 成本約 NT$2,500。
最有意思的不是技術指標,是使用樣態:
- 客服用它在電話中即時查政策門檻
- 新人把它當自助 onboarding 工具 —— HR 少了很多「表單在哪裡」的中斷
- 一群進階使用者內化了
#發布流程,這個 Bot 變成他們主要的知識貢獻入口
知識庫本身的成長速度比以前快。不是因為有人被要求要寫,而是因為門檻降低到讓「貢獻」變成「使用副作用」。
踩過的坑(學到的東西)
幾個必須真實上線才會浮出的問題:
node-cron會悄悄失效。長時間運行的 process 下,整點排程會「不知不覺停了」,但短週期排程(*/5)照樣活著。我第一次上的修法「理論上有用」,但只在重啟時生效 —— 而 Bot 沒重啟。真正的解法:用 10 分鐘輪詢做安全網,完全不依賴 cron。- Azure App Service 預設用 32-bit worker,Node heap 被砍到 90MB,跟
--max-old-space-size設多少無關。6000 個切片就 OOM。一行 CLI 就能切換。 - wwwroot 在 zip-deploy 時會被清空,包括
data/如果你把 vector store 放那。曾經因此整個知識庫消失。解法:用 env 變數把路徑指向持久化目錄。 - Teams 傳來的 content-type 是
image/*(通配符,不是實際 mime),而且contentUrl需要 Bearer 認證才能下載。一連串錯誤假設要慢慢拆掉。
完整的 postmortem 在 repo 裡,包含架構選擇、和我會重做的部分。
接下來想加什麼
- 圖片 OCR:很多 SOP 把關鍵資訊放在截圖裡,純文字 RAG 看不到。在同步階段對圖片做一次 vision pass。
- 混合搜尋(BM25 + dense):對專有名詞、ID 字串,純 dense retrieval 是真的弱。
- 可換的 LLM provider:現在綁 Azure OpenAI 是有實務理由的(亞洲直連 OpenAI / Anthropic 會 403),但抽象一層 interface 就能換到 OpenAI / Anthropic / Bedrock。
技術棧
TypeScript、Node.js、Azure OpenAI(gpt-4.1 + text-embedding-3-small)、Microsoft Bot Framework、Wiki.js GraphQL、Google Drive API + Docs API、Notion API、Azure Blob Storage、Azure SQL、Application Insights。部署在 Azure App Service。
原始碼在 GitHub —— README 有完整的架構說明,需要技術細節可以看。